Overview¶
Alphalens is designed to aid in the analysis of “alpha factors,” data transformations that are used to predict future price movements of financial instruments. Alpha factors take the form of a single value for each asset on each day. The dimension of these values is not necessarily important. We evaluate an alpha factor by considering daily factor values relative to one another.
It is important to note the difference between an alpha factor and a trading algorithm. A trading algorithm uses an alpha factor, or combination of alpha factors to generate trades. Trading algorithms cover execution and risk constraints: the business of turning predictions into profits. Alpha factors, on the other hand, are focused soley on making predictions. This difference in scope lends itself to a difference in the methodologies used to evaluate alpha factors and trading algorithms.
Alphalens does not contain analyses of things like transaction costs, capacity, or portfolio construction. Those interested in more implementation specific analyses are encouaged to check out pyfolio, a library specifically geared towards the evaluation of trading algorithms.
Imports & Settings¶
[1]:
import warnings
warnings.filterwarnings('ignore')
[3]:
import pandas as pd
import alphalens
import seaborn as sns
[4]:
%matplotlib inline
sns.set_style('white')
Load & Transform Data¶
[5]:
ticker_sector = {
"ACN": 0, "ATVI": 0, "ADBE": 0, "AMD": 0, "AKAM": 0, "ADS": 0, "GOOGL": 0, "GOOG": 0,
"APH": 0, "ADI": 0, "ANSS": 0, "AAPL": 0, "AMAT": 0, "ADSK": 0, "ADP": 0, "AVGO": 0,
"AMG": 1, "AFL": 1, "ALL": 1, "AXP": 1, "AIG": 1, "AMP": 1, "AON": 1, "AJG": 1, "AIZ": 1, "BAC": 1,
"BK": 1, "BBT": 1, "BRK.B": 1, "BLK": 1, "HRB": 1, "BHF": 1, "COF": 1, "CBOE": 1, "SCHW": 1, "CB": 1,
"ABT": 2, "ABBV": 2, "AET": 2, "A": 2, "ALXN": 2, "ALGN": 2, "AGN": 2, "ABC": 2, "AMGN": 2, "ANTM": 2,
"BCR": 2, "BAX": 2, "BDX": 2, "BIIB": 2, "BSX": 2, "BMY": 2, "CAH": 2, "CELG": 2, "CNC": 2, "CERN": 2,
"MMM": 3, "AYI": 3, "ALK": 3, "ALLE": 3, "AAL": 3, "AME": 3, "AOS": 3, "ARNC": 3, "BA": 3, "CHRW": 3,
"CAT": 3, "CTAS": 3, "CSX": 3, "CMI": 3, "DE": 3, "DAL": 3, "DOV": 3, "ETN": 3, "EMR": 3, "EFX": 3,
"AES": 4, "LNT": 4, "AEE": 4, "AEP": 4, "AWK": 4, "CNP": 4, "CMS": 4, "ED": 4, "D": 4, "DTE": 4,
"DUK": 4, "EIX": 4, "ETR": 4, "ES": 4, "EXC": 4, "FE": 4, "NEE": 4, "NI": 4, "NRG": 4, "PCG": 4,
"ARE": 5, "AMT": 5, "AIV": 5, "AVB": 5, "BXP": 5, "CBG": 5, "CCI": 5, "DLR": 5, "DRE": 5,
"EQIX": 5, "EQR": 5, "ESS": 5, "EXR": 5, "FRT": 5, "GGP": 5, "HCP": 5, "HST": 5, "IRM": 5, "KIM": 5,
"APD": 6, "ALB": 6, "AVY": 6, "BLL": 6, "CF": 6, "DWDP": 6, "EMN": 6, "ECL": 6, "FMC": 6, "FCX": 6,
"IP": 6, "IFF": 6, "LYB": 6, "MLM": 6, "MON": 6, "MOS": 6, "NEM": 6, "NUE": 6, "PKG": 6, "PPG": 6,
"T": 7, "CTL": 7, "VZ": 7,
"MO": 8, "ADM": 8, "BF.B": 8, "CPB": 8, "CHD": 8, "CLX": 8, "KO": 8, "CL": 8, "CAG": 8,
"STZ": 8, "COST": 8, "COTY": 8, "CVS": 8, "DPS": 8, "EL": 8, "GIS": 8, "HSY": 8, "HRL": 8,
"AAP": 9, "AMZN": 9, "APTV": 9, "AZO": 9, "BBY": 9, "BWA": 9, "KMX": 9, "CCL": 9,
"APC": 10, "ANDV": 10, "APA": 10, "BHGE": 10, "COG": 10, "CHK": 10, "CVX": 10, "XEC": 10, "CXO": 10,
"COP": 10, "DVN": 10, "EOG": 10, "EQT": 10, "XOM": 10, "HAL": 10, "HP": 10, "HES": 10, "KMI": 10
}
See yfinance for details.
[6]:
import yfinance as yf
import pandas_datareader.data as web
yf.pdr_override()
tickers = list(ticker_sector.keys())
df = web.get_data_yahoo(tickers, start='2014-12-01', end='2017-01-01')
df.index = pd.to_datetime(df.index, utc=True)
[*********************100%***********************] 182 of 182 completed
19 Failed downloads:
- DPS: No data found for this date range, symbol may be delisted
- CBG: No data found for this date range, symbol may be delisted
- CHK: Data doesn't exist for startDate = 1417413600, endDate = 1483250400
- CELG: No data found, symbol may be delisted
- ARNC: Data doesn't exist for startDate = 1417413600, endDate = 1483250400
- BRK.B: No data found, symbol may be delisted
- AGN: No data found, symbol may be delisted
- CXO: No data found, symbol may be delisted
- MON: Data doesn't exist for startDate = 1417413600, endDate = 1483250400
- BCR: No data found for this date range, symbol may be delisted
- DWDP: No data found, symbol may be delisted
- CTL: No data found, symbol may be delisted
- APC: No data found, symbol may be delisted
- GGP: No data found for this date range, symbol may be delisted
- HCP: No data found, symbol may be delisted
- BHF: Data doesn't exist for startDate = 1417413600, endDate = 1483250400
- BHGE: No data found, symbol may be delisted
- BF.B: No data found for this date range, symbol may be delisted
- BBT: No data found, symbol may be delisted
[7]:
df = df.stack()
df.index.names = ['date', 'asset']
df.info()
<class 'pandas.core.frame.DataFrame'>
MultiIndex: 85738 entries, (Timestamp('2014-12-01 00:00:00+0000', tz='UTC'), 'A') to (Timestamp('2016-12-30 00:00:00+0000', tz='UTC'), 'XOM')
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Adj Close 85738 non-null float64
1 Close 85738 non-null float64
2 High 85738 non-null float64
3 Low 85738 non-null float64
4 Open 85738 non-null float64
5 Volume 85738 non-null float64
dtypes: float64(6)
memory usage: 4.3+ MB
Compute Factor¶
For demonstration purposes we will create a predictive factor. To cheat we will look at future prices to make sure we’ll rank high stoks that will perform well and vice versa.
[8]:
lookahead_bias_days = 5
predictive_factor = df.loc[:, 'Open'].unstack('asset')
predictive_factor = predictive_factor.pct_change(lookahead_bias_days)
# introduce look-ahead bias and make the factor predictive
predictive_factor = predictive_factor.shift(-lookahead_bias_days)
predictive_factor = predictive_factor.stack()
[9]:
predictive_factor.head()
[9]:
date asset
2014-12-01 00:00:00+00:00 A -0.010775
AAL 0.029388
AAP 0.057920
AAPL -0.039643
ABBV 0.010567
dtype: float64
Get pricing info¶
The pricing data passed to alphalens should contain the entry price for the assets so it must reflect the next available price after a factor value was observed at a given timestamp. Those prices must not be used in the calculation of the factor values for that time. Always double check to ensure you are not introducing lookahead bias to your study.
The pricing data must also contain the exit price for the assets, for period 1 the price at the next timestamp will be used, for period 2 the price after 2 timestats will be used and so on.
There are no restrinctions/assumptions on the time frequencies a factor should be computed at and neither on the specific time a factor should be traded (trading at the open vs trading at the close vs intraday trading), it is only required that factor and price DataFrames are properly aligned given the rules above.
In our example, before the trading starts every day, we observe yesterday factor values. The price we pass to alphalens is the next available price after that factor observation: the daily open price that will be used as assets entry price. Also, we are not adding additional prices so the assets exit price will be the following days open prices (how many days depends on ‘periods’ argument). The retuns computed by Alphalens will therefore based on assets open prices.
[10]:
pricing = df.loc[:, 'Open'].iloc[1:].unstack('asset')
pricing.head()
[10]:
| asset | AAL | AAP | AAPL | ABBV | ABC | ABT | ACN | ADBE | ADI | ADM | ... | PCG | PKG | PPG | SCHW | STZ | T | VZ | XEC | XOM | A |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| date | |||||||||||||||||||||
| 2014-12-01 00:00:00+00:00 | 49.000000 | 146.410004 | 29.702499 | 69.080002 | 90.639999 | 44.270000 | 85.879997 | 73.639999 | 54.480000 | 52.660000 | ... | 50.209999 | 74.250000 | 108.730003 | 28.080000 | 95.820000 | 35.279999 | 50.680000 | 103.980003 | 90.360001 | NaN |
| 2014-12-02 00:00:00+00:00 | 48.119999 | 146.710007 | 28.375000 | 68.879997 | 90.930000 | 44.680000 | 85.849998 | 74.000000 | 54.540001 | 52.740002 | ... | 50.689999 | 73.209999 | 110.605003 | 27.860001 | 94.930000 | 34.889999 | 49.799999 | 102.790001 | 92.320000 | 41.599998 |
| 2014-12-03 00:00:00+00:00 | 47.740002 | 148.440002 | 28.937500 | 69.169998 | 91.989998 | 45.220001 | 86.400002 | 73.639999 | 54.950001 | 53.330002 | ... | 51.500000 | 74.779999 | 109.800003 | 28.200001 | 94.260002 | 34.250000 | 49.020000 | 103.809998 | 94.669998 | 41.980000 |
| 2014-12-04 00:00:00+00:00 | 49.599998 | 152.419998 | 28.942499 | 68.349998 | 91.870003 | 45.660000 | 86.410004 | 73.089996 | 56.459999 | 53.270000 | ... | 50.910000 | 76.760002 | 111.555000 | 28.940001 | 94.010002 | 34.080002 | 48.730000 | 105.550003 | 94.129997 | 42.150002 |
| 2014-12-05 00:00:00+00:00 | 50.090000 | 154.210007 | 28.997499 | 69.519997 | 92.379997 | 45.430000 | 86.309998 | 73.160004 | 56.750000 | 52.750000 | ... | 49.860001 | 77.790001 | 111.949997 | 29.770000 | 94.250000 | 33.880001 | 48.680000 | 106.860001 | 93.949997 | 42.230000 |
5 rows × 163 columns
Often, we’d want to know how our factor looks across various groupings (sectors, industires, countries, etc.), in this example let’s use sectors. To generate sector level breakdowns, you’ll need to pass alphalens a sector mapping for each traded name.
This mapping can come in the form of a MultiIndexed Series (with the same date/symbol index as your factor value) if you want to provide a sector mapping for each symbol on each day.
If you’d like to use constant sector mappings, you may pass symbol to sector mappings as a dict.
If your sector mappings come in the form of codes (as they do in this tutorial), you may also pass alphalens a dict of sector names to use in place of sector codes.
[11]:
sector_names = {
0: "information_technology",
1: "financials",
2: "health_care",
3: "industrials",
4: "utilities",
5: "real_estate",
6: "materials",
7: "telecommunication_services",
8: "consumer_staples",
9: "consumer_discretionary",
10: "energy"
}
Format tearsheet input data¶
Alphalens contains a handy data formatting function to transform your factor and pricing data into the exact inputs expected by the tear sheet functions.
[12]:
factor_data = alphalens.utils.get_clean_factor_and_forward_returns(predictive_factor,
pricing,
quantiles=5,
bins=None,
groupby=ticker_sector,
groupby_labels=sector_names)
Dropped 1.0% entries from factor data: 1.0% in forward returns computation and 0.0% in binning phase (set max_loss=0 to see potentially suppressed Exceptions).
max_loss is 35.0%, not exceeded: OK!
The function inform the user how much data was dropped after formatting the input data. Factor data can be partially dropped due to being flawed itself (e.g. NaNs), not having provided enough price data to compute forward returns for all factor values, or because it is not possible to perform binning. It is possible to control the maximum allowed data loss using ‘max_loss’ argument.
[13]:
factor_data.head()
[13]:
| 1D | 5D | 10D | factor | group | factor_quantile | ||
|---|---|---|---|---|---|---|---|
| date | asset | ||||||
| 2014-12-01 00:00:00+00:00 | AAL | -0.017959 | 0.029388 | 0.024694 | 0.029388 | industrials | 5 |
| AAP | 0.002049 | 0.057920 | 0.104433 | 0.057920 | consumer_discretionary | 5 | |
| AAPL | -0.044693 | -0.039643 | -0.068260 | -0.039643 | information_technology | 1 | |
| ABBV | -0.002895 | 0.010567 | -0.048205 | 0.010567 | health_care | 3 | |
| ABC | 0.003199 | 0.015115 | 0.010040 | 0.015115 | health_care | 4 |
You’ll notice that we’ve placed all of the information we need for our calculations into one dataframe. Variables are the columns, and observations are each row.
The integer columns represents the forward returns or the daily price change for the N days after a timestamp. The 1 day forward return for AAPL on 2014-12-2 is the percent change in the AAPL open price on 2014-12-2 and the AAPL open price on 2014-12-3. The 5 day forward return is the percent change from open 2014-12-2 to open 2014-12-9 (5 trading days) divided by 5.
Returns Analysis¶
Returns analysis gives us a raw description of a factor’s value that shows us the power of a factor in real currency values.
One of the most basic ways to look at a factor’s predictive power is to look at the mean return of different factor quantile.
Performance Metrics & Plotting Functions¶
[14]:
mean_return_by_q_daily, std_err = alphalens.performance.mean_return_by_quantile(
factor_data, by_date=True)
[15]:
mean_return_by_q_daily.head()
[15]:
| 1D | 5D | 10D | ||
|---|---|---|---|---|
| factor_quantile | date | |||
| 1 | 2014-12-01 00:00:00+00:00 | -0.011639 | -0.040503 | -0.048165 |
| 2014-12-02 00:00:00+00:00 | -0.001948 | -0.042854 | -0.051933 | |
| 2014-12-03 00:00:00+00:00 | -0.009176 | -0.048059 | -0.047047 | |
| 2014-12-04 00:00:00+00:00 | -0.003707 | -0.048854 | -0.025982 | |
| 2014-12-05 00:00:00+00:00 | -0.014295 | -0.057625 | -0.034734 |
[16]:
mean_return_by_q, std_err_by_q = alphalens.performance.mean_return_by_quantile(
factor_data, by_date=False)
[17]:
mean_return_by_q.head()
[17]:
| 1D | 5D | 10D | |
|---|---|---|---|
| factor_quantile | |||
| 1 | -0.008624 | -0.041080 | -0.041164 |
| 2 | -0.002719 | -0.013478 | -0.013805 |
| 3 | -0.000089 | -0.000332 | -0.000289 |
| 4 | 0.002760 | 0.012724 | 0.012964 |
| 5 | 0.008672 | 0.042145 | 0.042270 |
[20]:
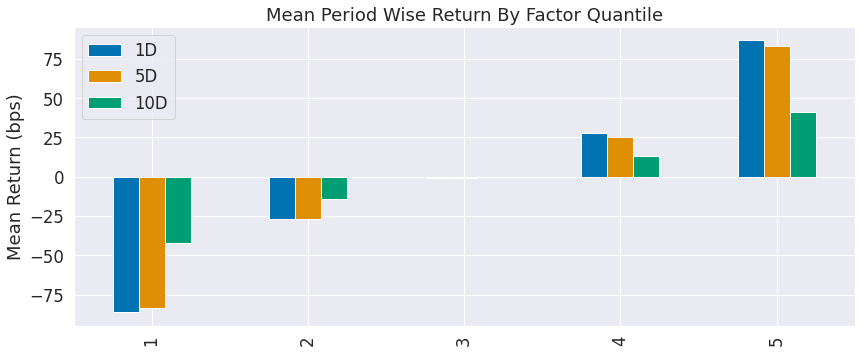
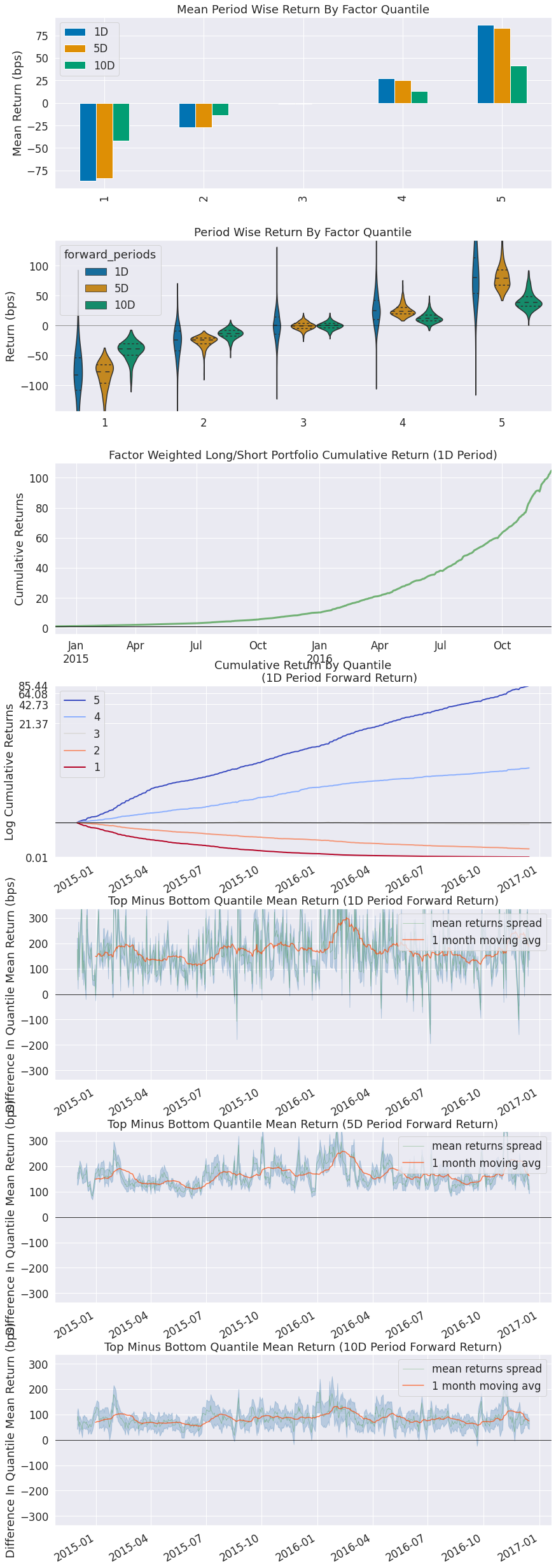
alphalens.plotting.plot_quantile_returns_bar(mean_return_by_q)
sns.despine()
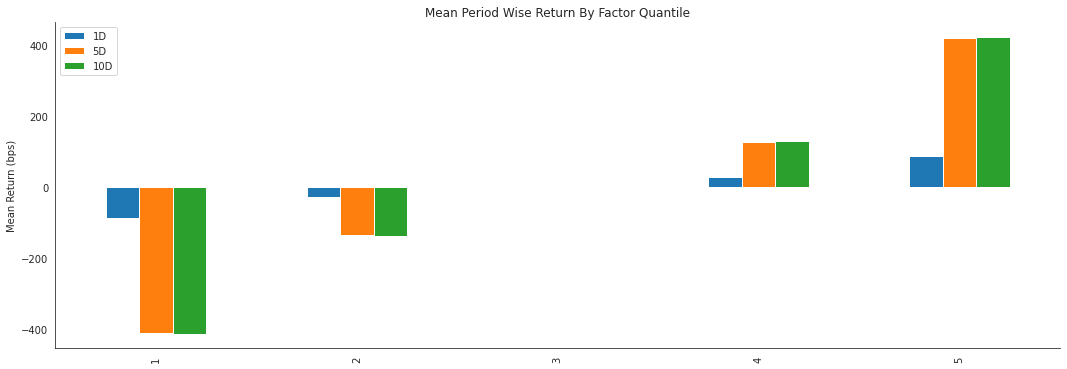
By looking at the mean return by quantile we can get a real look at how well the factor differentiates forward returns across the signal values. Obviously we want securities with a better signal to exhibit higher returns. For a good factor we’d expect to see negative values in the lower quartiles and positive values in the upper quantiles.
[21]:
alphalens.plotting.plot_quantile_returns_violin(mean_return_by_q_daily)
sns.despine()
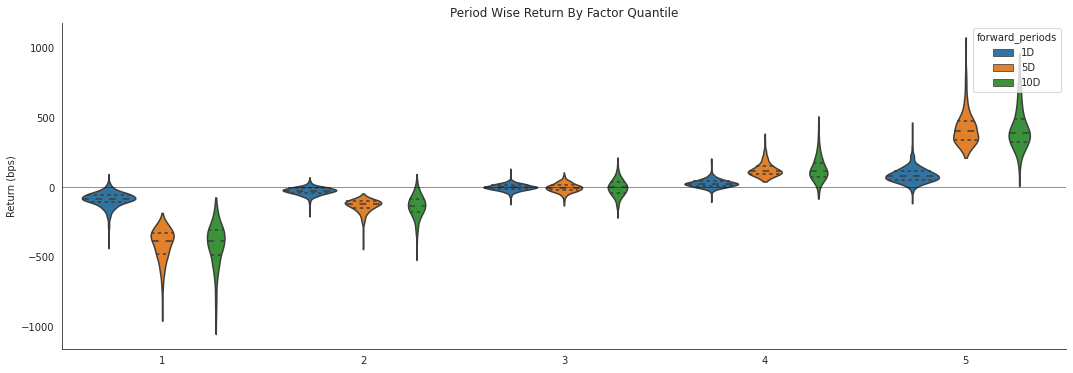
This violin plot is similar to the one before it but shows more information about the underlying data. It gives a better idea about the range of values, the median, and the inter-quartile range. What gives the plots their shape is the application of a probability density of the data at different values.
[22]:
quant_return_spread, std_err_spread = alphalens.performance.compute_mean_returns_spread(mean_return_by_q_daily,
upper_quant=5,
lower_quant=1,
std_err=std_err)
[24]:
alphalens.plotting.plot_mean_quantile_returns_spread_time_series(
quant_return_spread, std_err_spread);
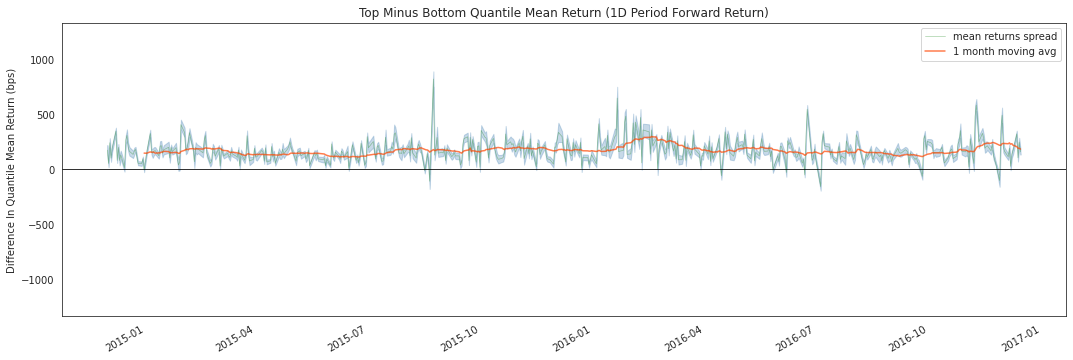
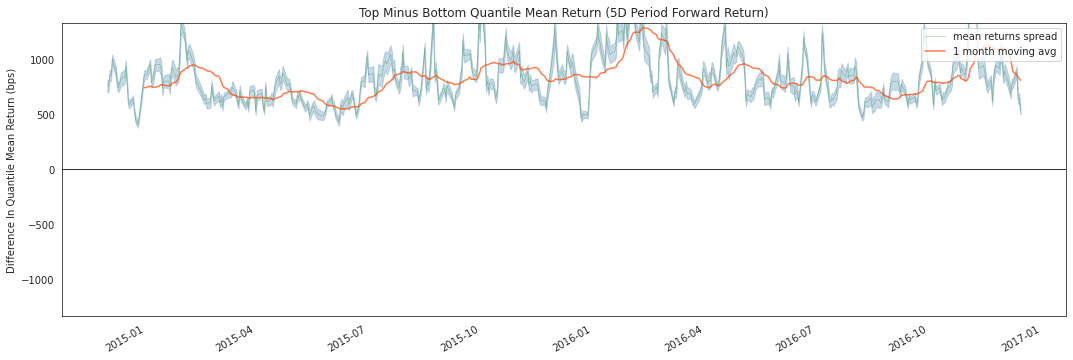
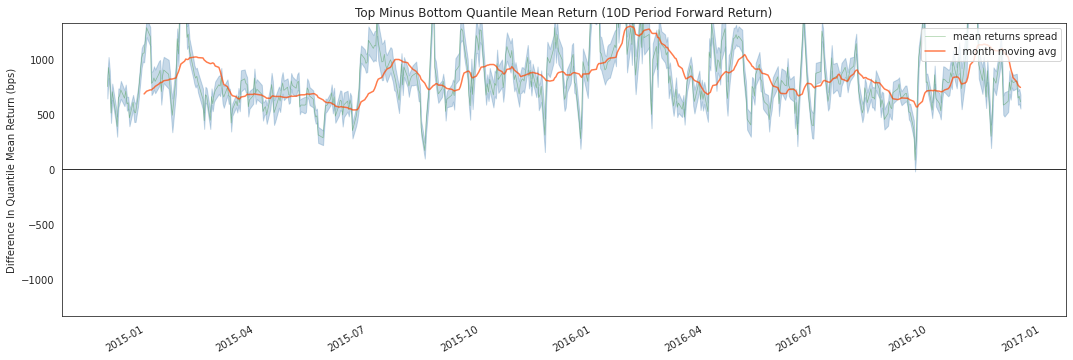
This rolling forward returns spread graph allows us to look at the raw spread in basis points between the top and bottom quantiles over time. The green line is the returns spread while the orange line is a 1 month average to smooth the data and make it easier to visualize.
[25]:
alphalens.plotting.plot_cumulative_returns_by_quantile(
mean_return_by_q_daily, period='1D');
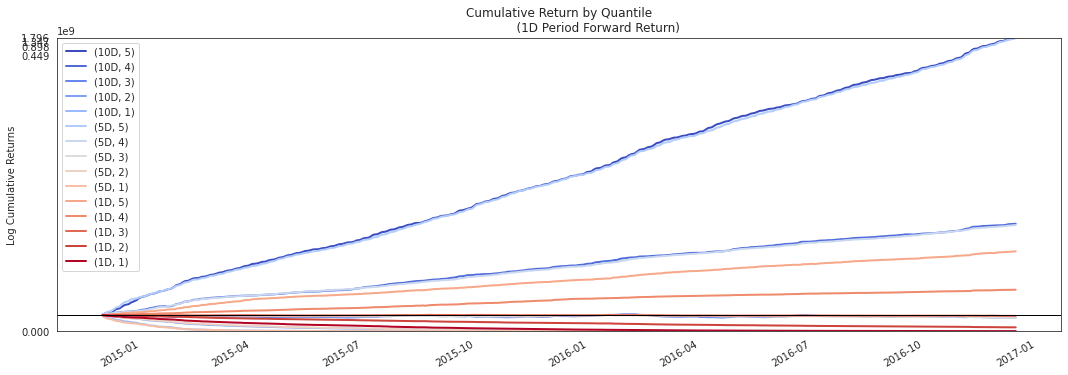
By looking at the cumulative returns by factor quantile we can get an intuition for which quantiles are contributing the most to the factor and at what time. Ideally we would like to see a these curves originate at the same value on the left and spread out like a fan as they move to the right through time, with the higher quantiles on the top.
[26]:
ls_factor_returns = alphalens.performance.factor_returns(factor_data)
[27]:
ls_factor_returns.head()
[27]:
| 1D | 5D | 10D | |
|---|---|---|---|
| date | |||
| 2014-12-01 00:00:00+00:00 | 0.009314 | 0.042049 | 0.041802 |
| 2014-12-02 00:00:00+00:00 | 0.003506 | 0.040637 | 0.046887 |
| 2014-12-03 00:00:00+00:00 | 0.012037 | 0.043812 | 0.041752 |
| 2014-12-04 00:00:00+00:00 | 0.004942 | 0.040428 | 0.028340 |
| 2014-12-05 00:00:00+00:00 | 0.009555 | 0.046433 | 0.031056 |
[28]:
alphalens.plotting.plot_cumulative_returns(
ls_factor_returns['1D'], period='1D');
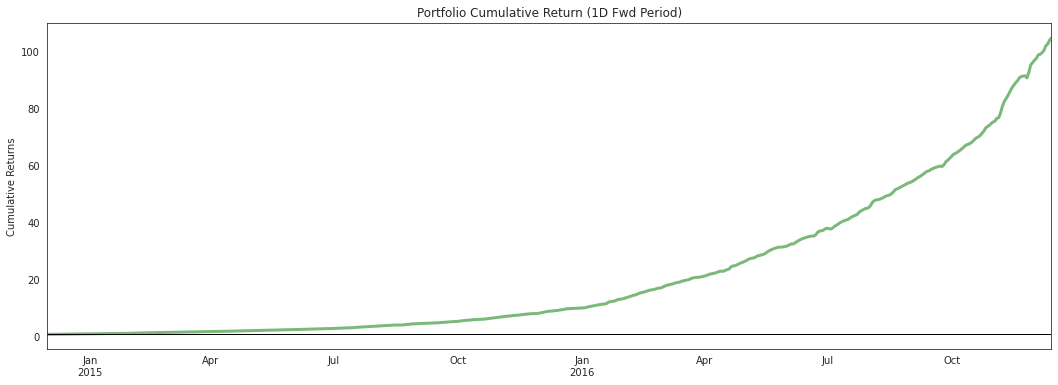
While looking at quantiles is important we must also look at the factor returns as a whole. The cumulative factor long/short returns plot lets us view the combined effects overtime of our entire factor.
[29]:
alpha_beta = alphalens.performance.factor_alpha_beta(factor_data)
[30]:
alpha_beta
[30]:
| 1D | 5D | 10D | |
|---|---|---|---|
| Ann. alpha | 8.656010 | 7.927868 | 1.985069 |
| beta | 0.093763 | 0.079954 | 0.061756 |
A very important part of factor returns analysis is determing the alpha, and how significant it is. Here we surface the annualized alpha, and beta.
Returns Tear Sheet¶
We can view all returns analysis calculations together.
[ ]:
alphalens.tears.create_returns_tear_sheet(factor_data)
Information Analysis¶
Information Analysis is a way for us to evaluate the predicitive value of a factor without the confounding effects of transaction costs. The main way we look at this is through the Information Coefficient (IC).
From Wikipedia…
The information coefficient (IC) is a measure of the merit of a predicted value. In finance, the information coefficient is used as a performance metric for the predictive skill of a financial analyst. The information coefficient is similar to correlation in that it can be seen to measure the linear relationship between two random variables, e.g. predicted stock returns and the actualized returns. The information coefficient ranges from 0 to 1, with 0 denoting no linear relationship between predictions and actual values (poor forecasting skills) and 1 denoting a perfect linear relationship (good forecasting skills).
Performance Metrics & Plotting Functions¶
[31]:
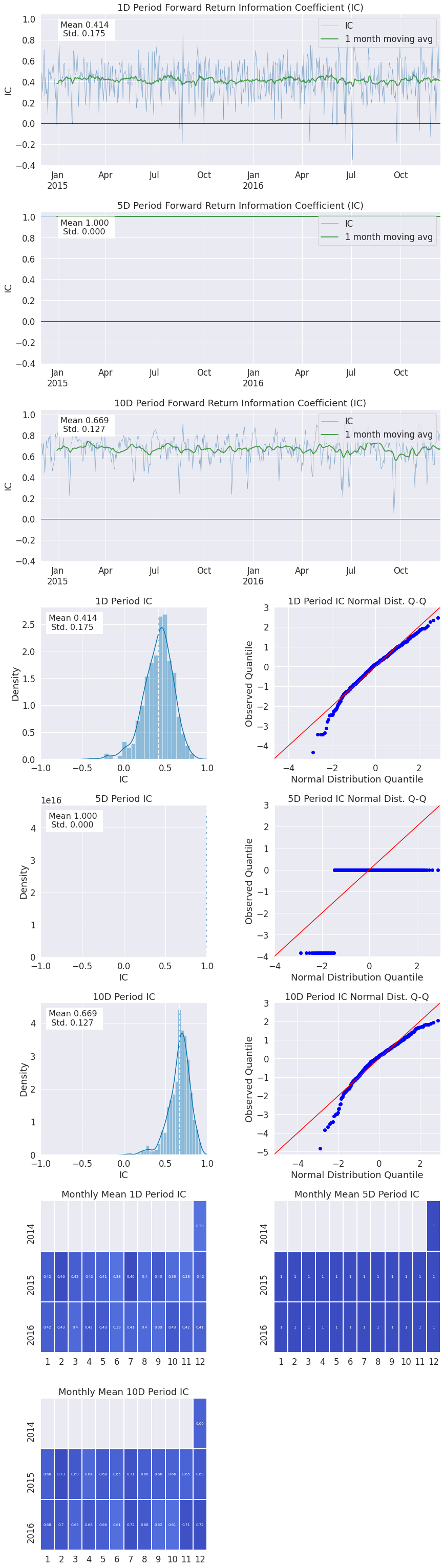
ic = alphalens.performance.factor_information_coefficient(factor_data)
[32]:
ic.head()
[32]:
| 1D | 5D | 10D | |
|---|---|---|---|
| date | |||
| 2014-12-01 00:00:00+00:00 | 0.355752 | 1.0 | 0.561977 |
| 2014-12-02 00:00:00+00:00 | 0.230225 | 1.0 | 0.718246 |
| 2014-12-03 00:00:00+00:00 | 0.485738 | 1.0 | 0.716855 |
| 2014-12-04 00:00:00+00:00 | 0.306327 | 1.0 | 0.609102 |
| 2014-12-05 00:00:00+00:00 | 0.485616 | 1.0 | 0.728141 |
[34]:
alphalens.plotting.plot_ic_ts(ic);
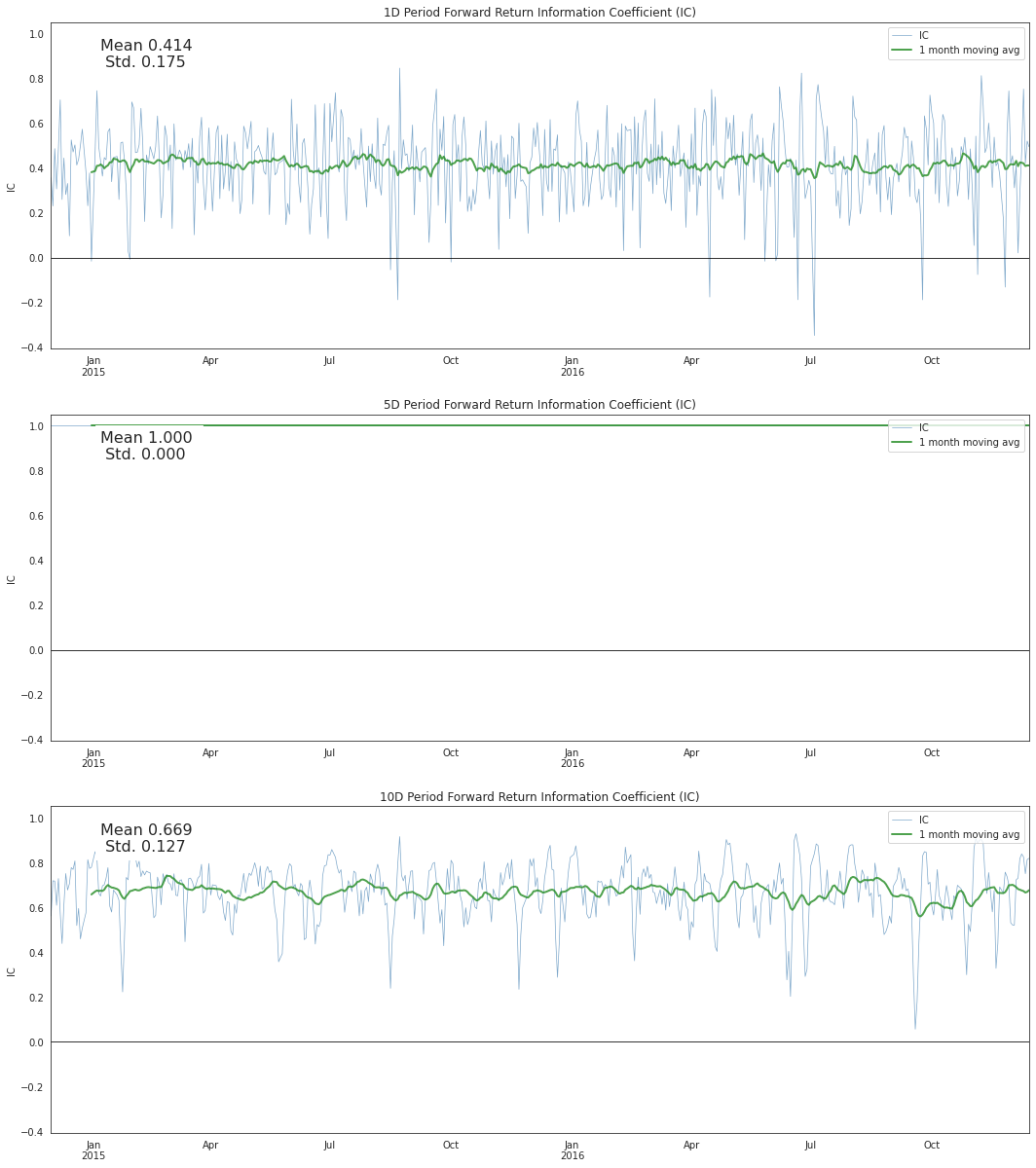
By looking at the IC each day we can understand how theoretically predicitive our factor is overtime. We like our mean IC to be high and the standard deviation, or volatility of it, to be low. We want to find consistently predictive factors.
[35]:
alphalens.plotting.plot_ic_hist(ic);
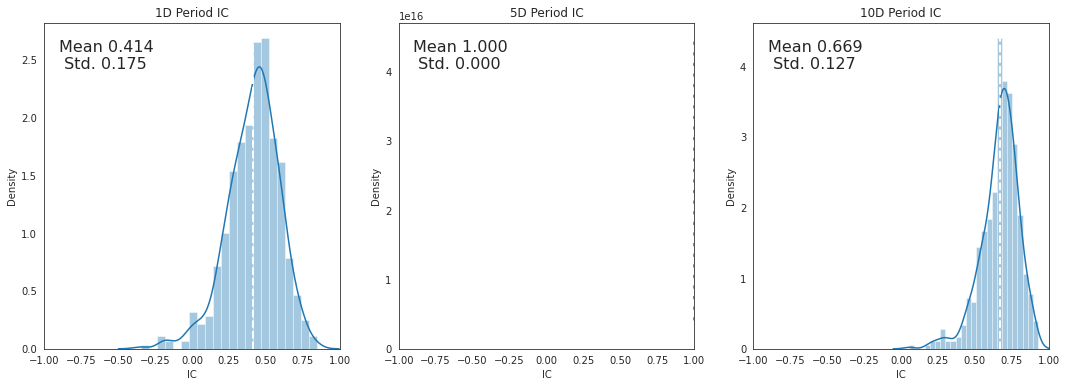
Looking at a histogram of the daily IC values can indicate how the factor behaves most of the time, where the likely IC values will fall, it also allows us to see if the factor has fat tails.
[36]:
alphalens.plotting.plot_ic_qq(ic);
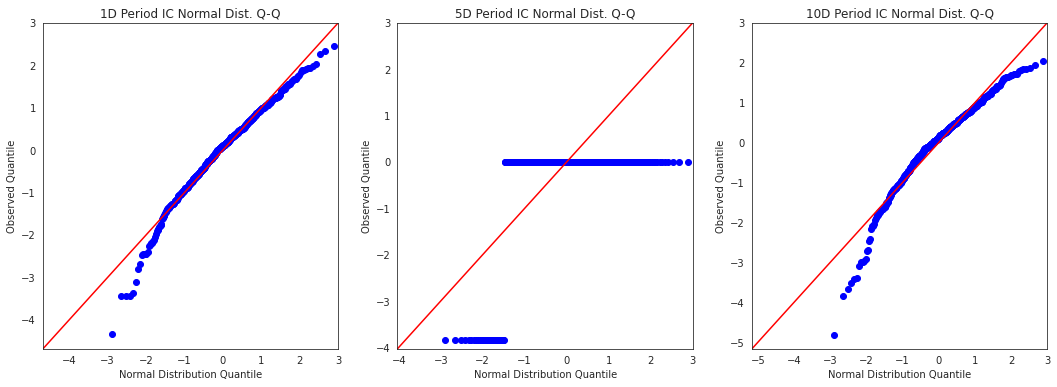
These Q-Q plots show the difference in shape between the distribution of IC values and a normal distribution. This is especially helpful in seeing how the most extreme values in the distribution affect the predicitive power.
[37]:
mean_monthly_ic = alphalens.performance.mean_information_coefficient(
factor_data, by_time='M')
[38]:
mean_monthly_ic.head()
[38]:
| 1D | 5D | 10D | |
|---|---|---|---|
| date | |||
| 2014-12-31 00:00:00+00:00 | 0.380726 | 1.0 | 0.657422 |
| 2015-01-31 00:00:00+00:00 | 0.424420 | 1.0 | 0.663536 |
| 2015-02-28 00:00:00+00:00 | 0.462670 | 1.0 | 0.729582 |
| 2015-03-31 00:00:00+00:00 | 0.423443 | 1.0 | 0.685343 |
| 2015-04-30 00:00:00+00:00 | 0.417112 | 1.0 | 0.638436 |
[39]:
alphalens.plotting.plot_monthly_ic_heatmap(mean_monthly_ic);
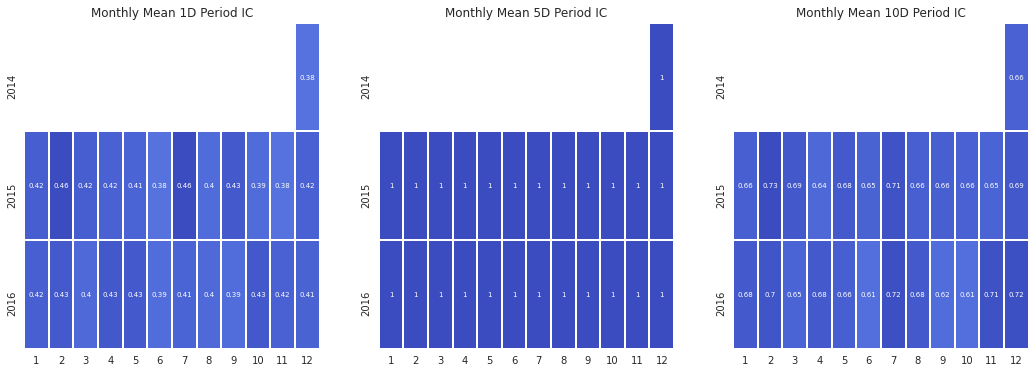
By displaying the IC data in heatmap format we can get an idea about the consistency of the factor, and how it behaves during different market regimes/seasons.
Information Tear Sheet¶
We can view all information analysis calculations together.
[40]:
alphalens.tears.create_information_tear_sheet(factor_data);
Information Analysis
| 1D | 5D | 10D | |
|---|---|---|---|
| IC Mean | 0.414 | 1.000000e+00 | 0.669 |
| IC Std. | 0.175 | 0.000000e+00 | 0.127 |
| Risk-Adjusted IC | 2.361 | 3.455090e+16 | 5.273 |
| t-stat(IC) | 53.633 | 7.848456e+17 | 119.777 |
| p-value(IC) | 0.000 | 0.000000e+00 | 0.000 |
| IC Skew | -0.673 | -3.840000e+00 | -1.034 |
| IC Kurtosis | 1.145 | 1.174300e+01 | 2.099 |
<Figure size 432x288 with 0 Axes>
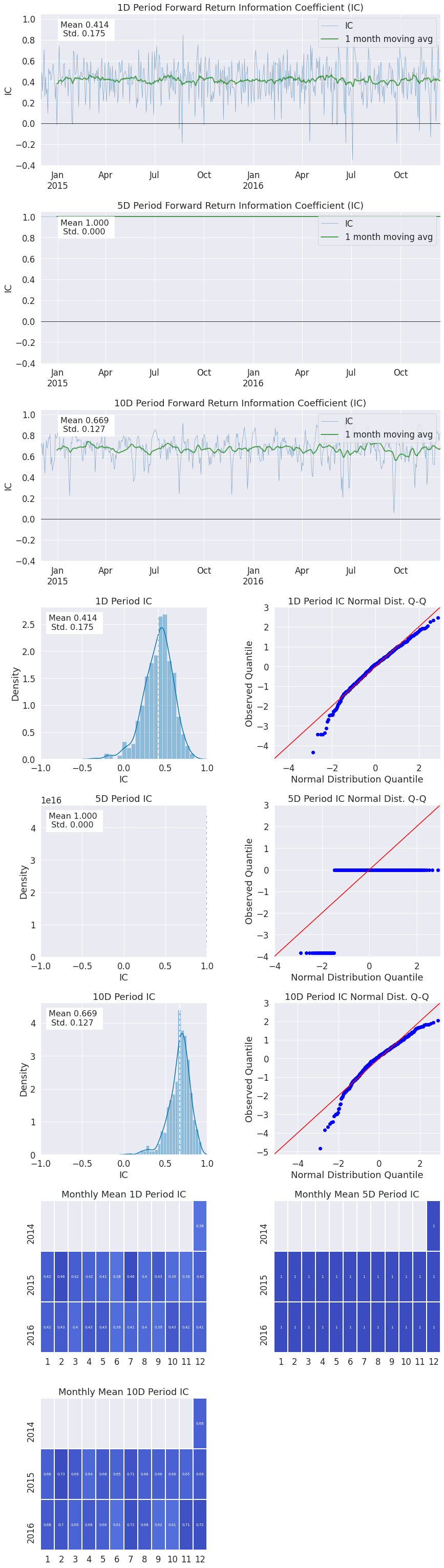
Turnover Analysis¶
Turnover Analysis gives us an idea about the nature of a factor’s makeup and how it changes.
Performance Metrics & Plotting Functions¶
[41]:
quantile_factor = factor_data['factor_quantile']
turnover_period = 1
[42]:
quantile_turnover = pd.concat([alphalens.performance.quantile_turnover(quantile_factor, q, turnover_period)
for q in range(1, int(quantile_factor.max()) + 1)], axis=1)
[43]:
quantile_turnover.head()
[43]:
| 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|
| date | |||||
| 2014-12-01 00:00:00+00:00 | NaN | NaN | NaN | NaN | NaN |
| 2014-12-02 00:00:00+00:00 | 0.333333 | 0.62500 | 0.666667 | 0.50000 | 0.424242 |
| 2014-12-03 00:00:00+00:00 | 0.151515 | 0.37500 | 0.545455 | 0.53125 | 0.393939 |
| 2014-12-04 00:00:00+00:00 | 0.181818 | 0.53125 | 0.757576 | 0.68750 | 0.424242 |
| 2014-12-05 00:00:00+00:00 | 0.151515 | 0.31250 | 0.515152 | 0.53125 | 0.606061 |
[44]:
alphalens.plotting.plot_top_bottom_quantile_turnover(
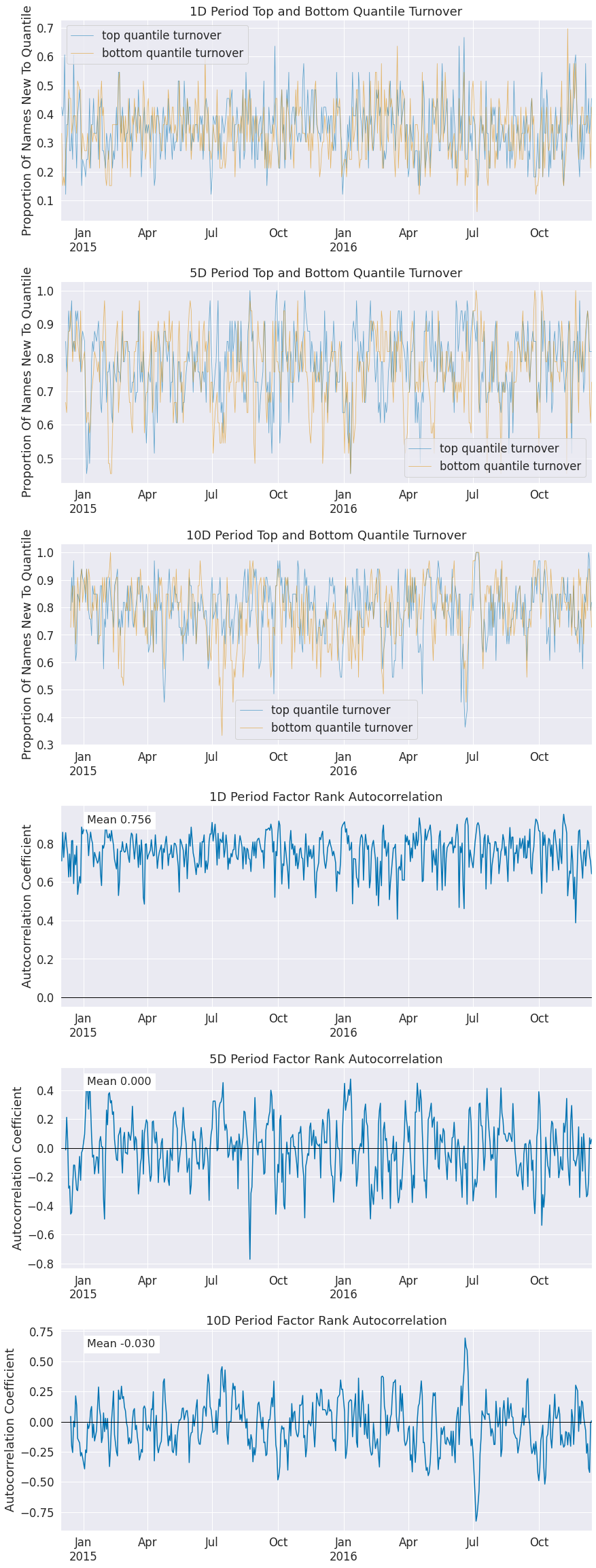
quantile_turnover, turnover_period);
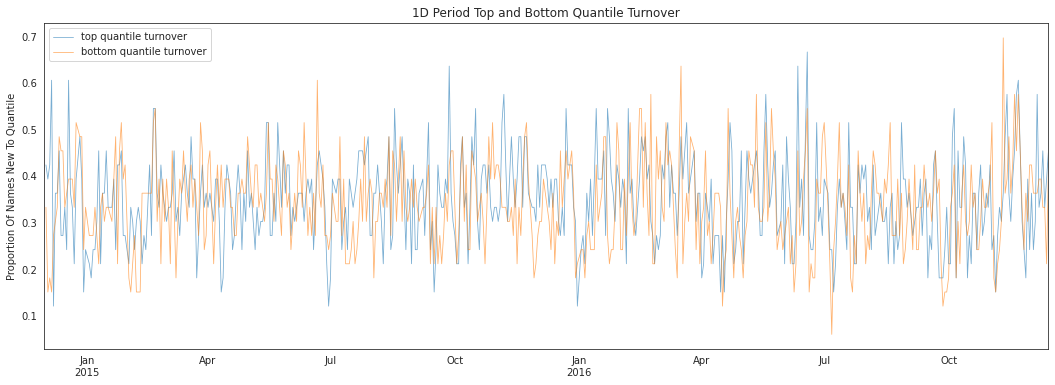
Factor turnover is important as it indicates the incorporation of new information and the make up of the extremes of a signal. By looking at the new additions to the sets of top and bottom quantiles we can see how much of this factor is getting remade everyday.
[45]:
factor_autocorrelation = alphalens.performance.factor_rank_autocorrelation(
factor_data, turnover_period)
[46]:
factor_autocorrelation.head()
[46]:
date
2014-12-01 00:00:00+00:00 NaN
2014-12-02 00:00:00+00:00 0.708640
2014-12-03 00:00:00+00:00 0.857790
2014-12-04 00:00:00+00:00 0.727252
2014-12-05 00:00:00+00:00 0.803030
Freq: C, Name: 1, dtype: float64
[47]:
alphalens.plotting.plot_factor_rank_auto_correlation(factor_autocorrelation);
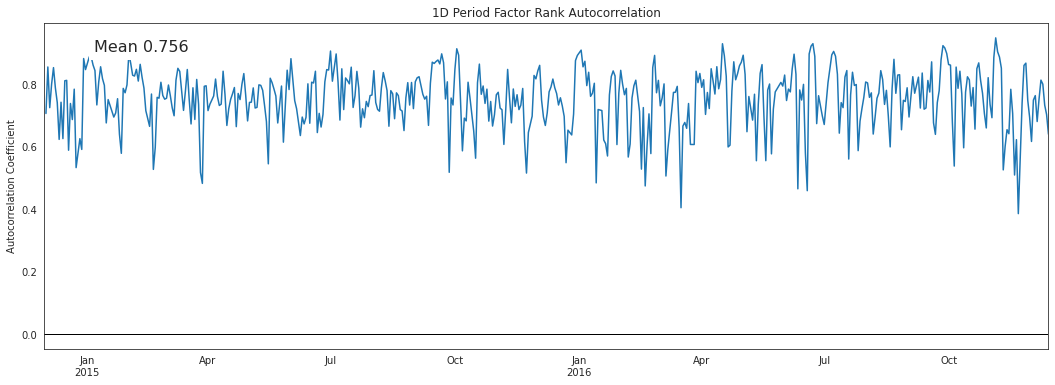
The autocorrelation of the factor indicates to us the persistence of the signal itself.
Turnover Tear Sheet¶
We can view all turnover calculations together.
[49]:
alphalens.tears.create_turnover_tear_sheet(factor_data);
Turnover Analysis
| 1D | 5D | 10D | |
|---|---|---|---|
| Quantile 1 Mean Turnover | 0.340 | 0.765 | 0.785 |
| Quantile 2 Mean Turnover | 0.601 | 0.791 | 0.799 |
| Quantile 3 Mean Turnover | 0.636 | 0.781 | 0.781 |
| Quantile 4 Mean Turnover | 0.607 | 0.791 | 0.800 |
| Quantile 5 Mean Turnover | 0.350 | 0.783 | 0.793 |
| 1D | 5D | 10D | |
|---|---|---|---|
| Mean Factor Rank Autocorrelation | 0.756 | 0.0 | -0.03 |
<Figure size 432x288 with 0 Axes>
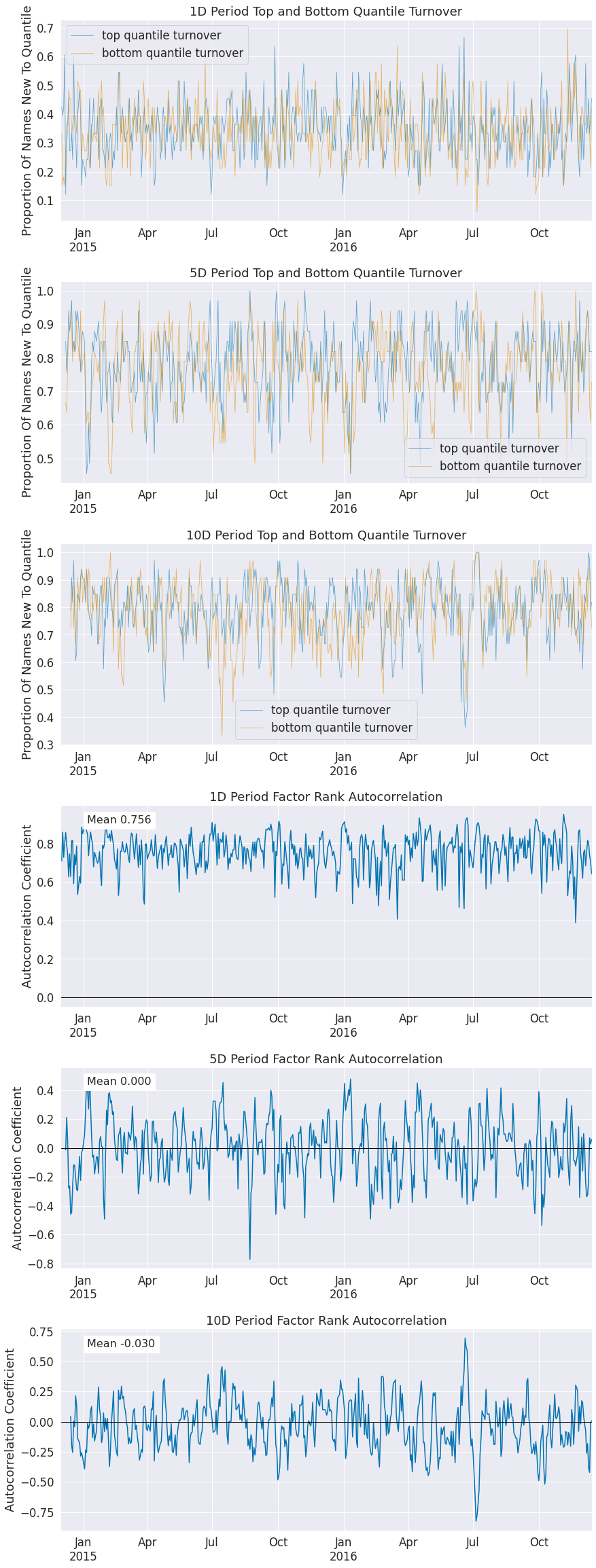
Event Style Returns Analysis¶
Looking at the average cumulative return in a window before and after a factor can indicate to us how long the predicative power of a factor lasts. This tear sheet takes a while to run.
NOTE: This tear sheet takes in an extra argument pricing.
[50]:
alphalens.tears.create_event_returns_tear_sheet(
factor_data, pricing, by_group=True);
<Figure size 432x288 with 0 Axes>
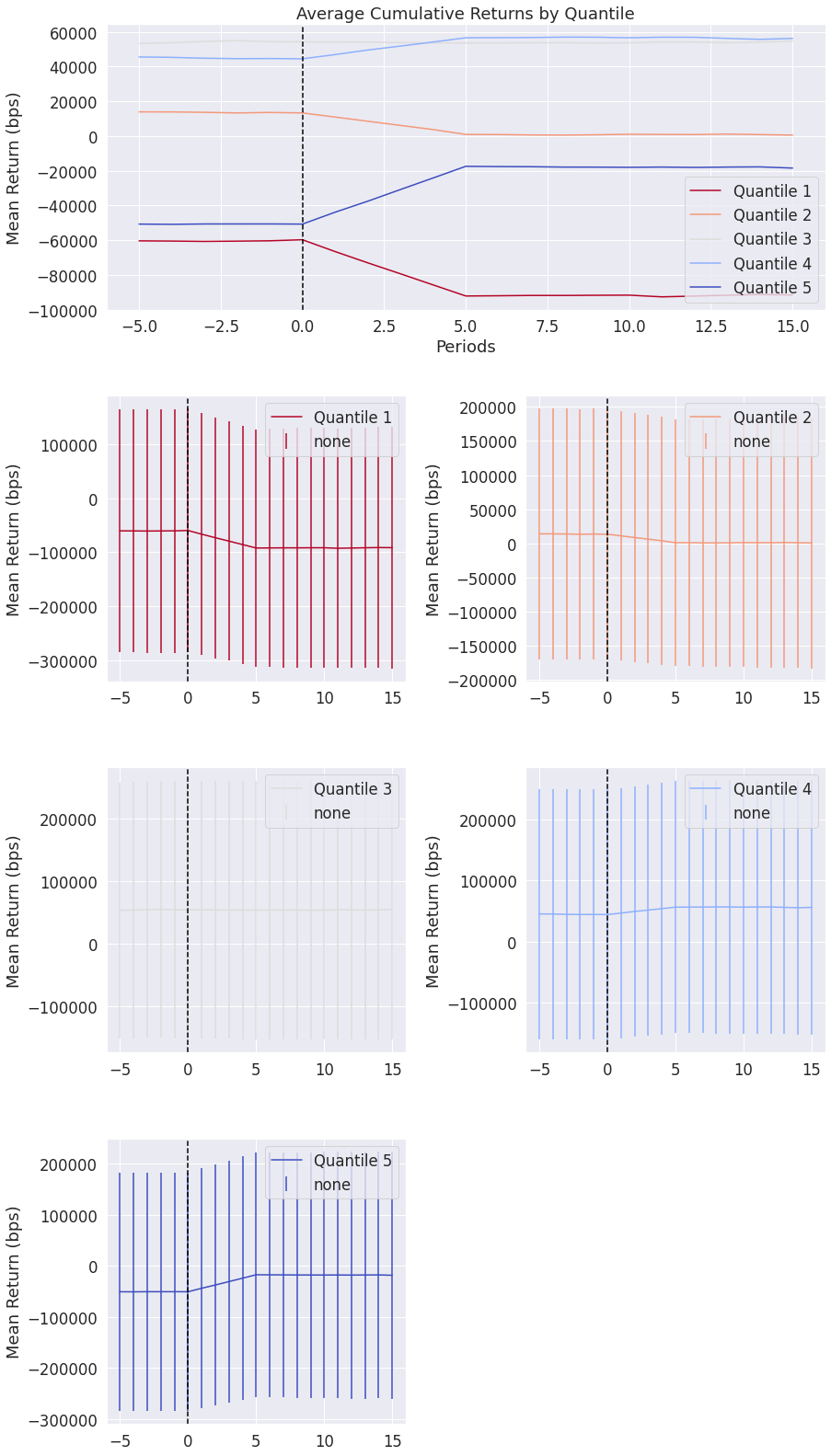
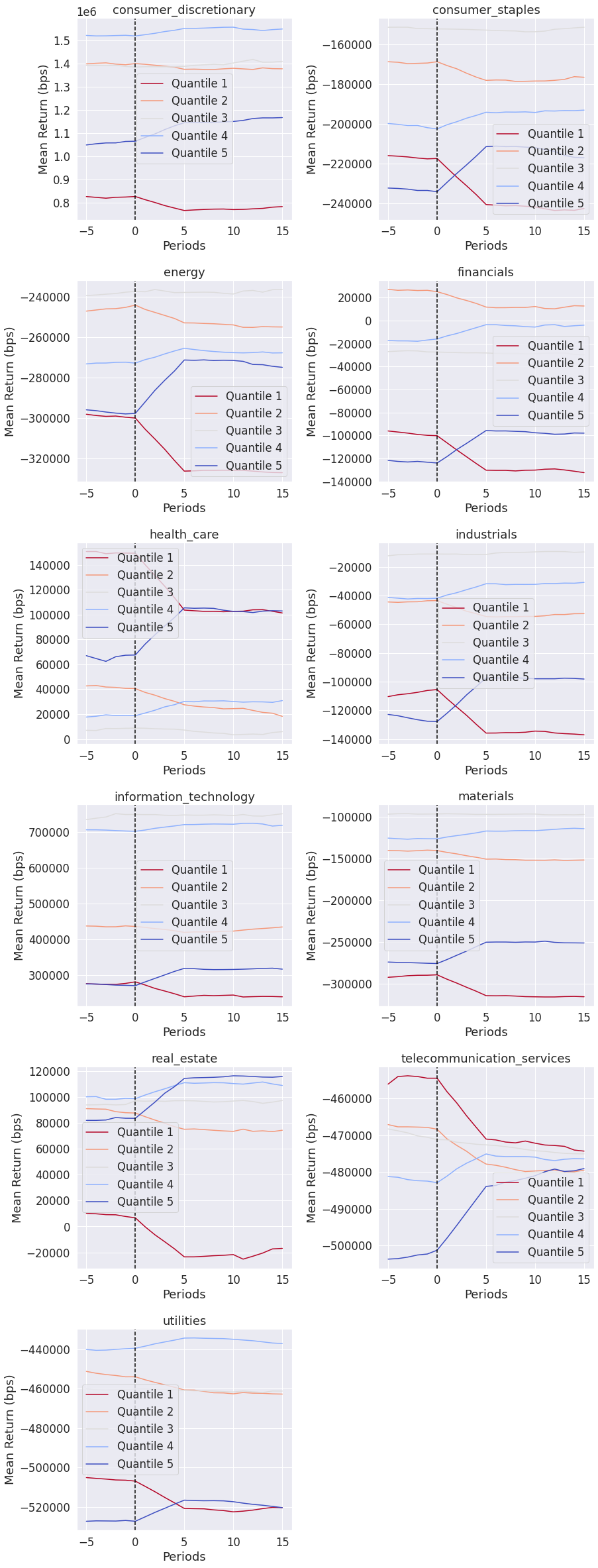
Groupwise Performance¶
Many of the plots in Alphalens can be viewed on their own by grouping if grouping information is provided. The returns and information tear sheets can be viewed groupwise by passing in the by_group=True argument.
[51]:
ic_by_sector = alphalens.performance.mean_information_coefficient(
factor_data, by_group=True)
[52]:
ic_by_sector.head()
[52]:
| 1D | 5D | 10D | |
|---|---|---|---|
| group | |||
| consumer_discretionary | 0.376525 | 1.0 | 0.630168 |
| consumer_staples | 0.388736 | 1.0 | 0.645816 |
| energy | 0.394440 | 1.0 | 0.634939 |
| financials | 0.404388 | 1.0 | 0.648418 |
| health_care | 0.388439 | 1.0 | 0.627040 |
[53]:
alphalens.plotting.plot_ic_by_group(ic_by_sector)
[53]:
<AxesSubplot:title={'center':'Information Coefficient By Group'}>
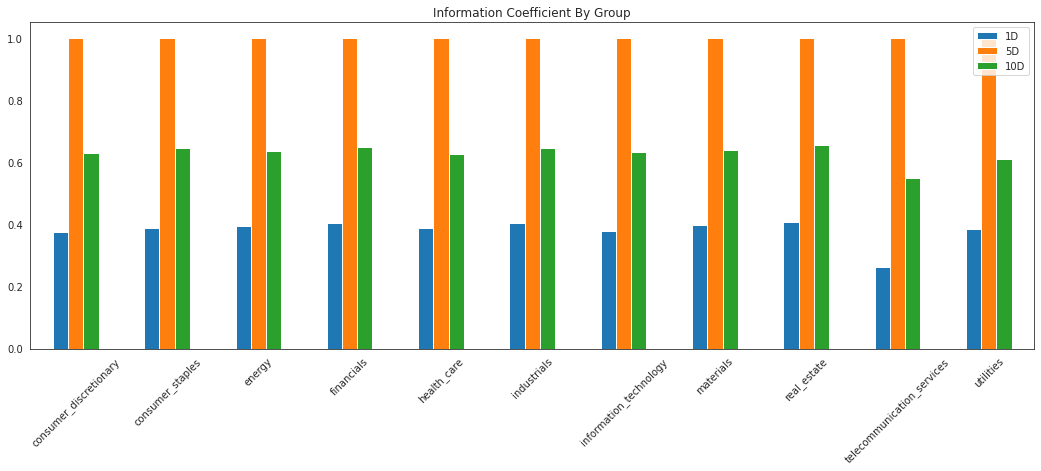
[54]:
mean_return_quantile_sector, mean_return_quantile_sector_err = alphalens.performance.mean_return_by_quantile(
factor_data, by_group=True)
[55]:
mean_return_quantile_sector.head()
[55]:
| 1D | 5D | 10D | ||
|---|---|---|---|---|
| factor_quantile | group | |||
| 1 | consumer_discretionary | -0.008481 | -0.042084 | -0.041998 |
| consumer_staples | -0.007378 | -0.035313 | -0.036838 | |
| energy | -0.009574 | -0.044188 | -0.043574 | |
| financials | -0.007825 | -0.038616 | -0.039761 | |
| health_care | -0.008552 | -0.041262 | -0.040898 |
[56]:
alphalens.plotting.plot_quantile_returns_bar(
mean_return_quantile_sector, by_group=True)
[56]:
array([<AxesSubplot:title={'center':'consumer_discretionary'}, ylabel='Mean Return (bps)'>,
<AxesSubplot:title={'center':'consumer_staples'}, ylabel='Mean Return (bps)'>,
<AxesSubplot:title={'center':'energy'}, ylabel='Mean Return (bps)'>,
<AxesSubplot:title={'center':'financials'}, ylabel='Mean Return (bps)'>,
<AxesSubplot:title={'center':'health_care'}, ylabel='Mean Return (bps)'>,
<AxesSubplot:title={'center':'industrials'}, ylabel='Mean Return (bps)'>,
<AxesSubplot:title={'center':'information_technology'}, ylabel='Mean Return (bps)'>,
<AxesSubplot:title={'center':'materials'}, ylabel='Mean Return (bps)'>,
<AxesSubplot:title={'center':'real_estate'}, ylabel='Mean Return (bps)'>,
<AxesSubplot:title={'center':'telecommunication_services'}, ylabel='Mean Return (bps)'>,
<AxesSubplot:title={'center':'utilities'}, ylabel='Mean Return (bps)'>,
<AxesSubplot:>], dtype=object)
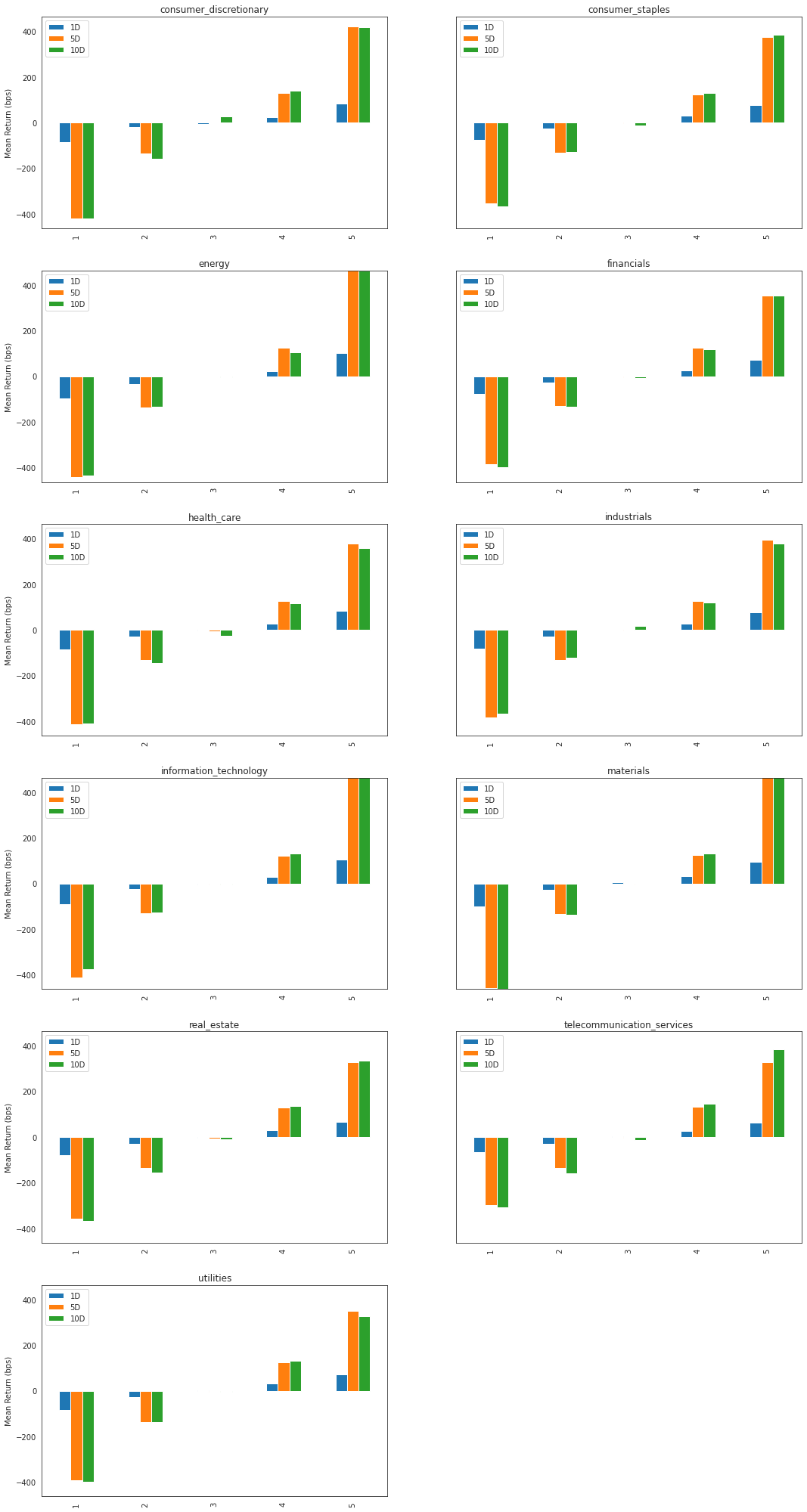
Summary Tear Sheet¶
There are a lot of plots above. If you want a quick snapshot of how the alpha factor performs consider the summary tear sheet.
[57]:
alphalens.tears.create_summary_tear_sheet(factor_data)
Quantiles Statistics
| min | max | mean | std | count | count % | |
|---|---|---|---|---|---|---|
| factor_quantile | ||||||
| 1 | -0.362876 | 0.034670 | -0.039407 | 0.032398 | 17028 | 20.245639 |
| 2 | -0.127588 | 0.046669 | -0.011804 | 0.019490 | 16513 | 19.633324 |
| 3 | -0.109737 | 0.068948 | 0.001341 | 0.018291 | 17026 | 20.243262 |
| 4 | -0.087449 | 0.098542 | 0.014397 | 0.019180 | 16512 | 19.632135 |
| 5 | -0.061661 | 0.494950 | 0.043818 | 0.036501 | 17028 | 20.245639 |
Returns Analysis
| 1D | 5D | 10D | |
|---|---|---|---|
| Ann. alpha | 8.656 | 7.928 | 1.985 |
| beta | 0.094 | 0.080 | 0.062 |
| Mean Period Wise Return Top Quantile (bps) | 86.725 | 82.903 | 41.487 |
| Mean Period Wise Return Bottom Quantile (bps) | -86.236 | -83.545 | -41.947 |
| Mean Period Wise Spread (bps) | 172.960 | 166.458 | 83.458 |
Information Analysis
| 1D | 5D | 10D | |
|---|---|---|---|
| IC Mean | 0.414 | 1.000000e+00 | 0.669 |
| IC Std. | 0.175 | 0.000000e+00 | 0.127 |
| Risk-Adjusted IC | 2.361 | 3.455090e+16 | 5.273 |
| t-stat(IC) | 53.633 | 7.848456e+17 | 119.777 |
| p-value(IC) | 0.000 | 0.000000e+00 | 0.000 |
| IC Skew | -0.673 | -3.840000e+00 | -1.034 |
| IC Kurtosis | 1.145 | 1.174300e+01 | 2.099 |
Turnover Analysis
| 1D | 5D | 10D | |
|---|---|---|---|
| Quantile 1 Mean Turnover | 0.340 | 0.765 | 0.785 |
| Quantile 2 Mean Turnover | 0.601 | 0.791 | 0.799 |
| Quantile 3 Mean Turnover | 0.636 | 0.781 | 0.781 |
| Quantile 4 Mean Turnover | 0.607 | 0.791 | 0.800 |
| Quantile 5 Mean Turnover | 0.350 | 0.783 | 0.793 |
| 1D | 5D | 10D | |
|---|---|---|---|
| Mean Factor Rank Autocorrelation | 0.756 | 0.0 | -0.03 |
<Figure size 432x288 with 0 Axes>
The Whole Thing¶
If you want to see all of the results create a full tear sheet. By passing in the factor data you can analyze all of the above statistics and plots at once.
[58]:
alphalens.tears.create_full_tear_sheet(factor_data)
Quantiles Statistics
| min | max | mean | std | count | count % | |
|---|---|---|---|---|---|---|
| factor_quantile | ||||||
| 1 | -0.362876 | 0.034670 | -0.039407 | 0.032398 | 17028 | 20.245639 |
| 2 | -0.127588 | 0.046669 | -0.011804 | 0.019490 | 16513 | 19.633324 |
| 3 | -0.109737 | 0.068948 | 0.001341 | 0.018291 | 17026 | 20.243262 |
| 4 | -0.087449 | 0.098542 | 0.014397 | 0.019180 | 16512 | 19.632135 |
| 5 | -0.061661 | 0.494950 | 0.043818 | 0.036501 | 17028 | 20.245639 |
Returns Analysis
| 1D | 5D | 10D | |
|---|---|---|---|
| Ann. alpha | 8.656 | 7.928 | 1.985 |
| beta | 0.094 | 0.080 | 0.062 |
| Mean Period Wise Return Top Quantile (bps) | 86.725 | 82.903 | 41.487 |
| Mean Period Wise Return Bottom Quantile (bps) | -86.236 | -83.545 | -41.947 |
| Mean Period Wise Spread (bps) | 172.960 | 166.458 | 83.458 |
<Figure size 432x288 with 0 Axes>
Information Analysis
| 1D | 5D | 10D | |
|---|---|---|---|
| IC Mean | 0.414 | 1.000000e+00 | 0.669 |
| IC Std. | 0.175 | 0.000000e+00 | 0.127 |
| Risk-Adjusted IC | 2.361 | 3.455090e+16 | 5.273 |
| t-stat(IC) | 53.633 | 7.848456e+17 | 119.777 |
| p-value(IC) | 0.000 | 0.000000e+00 | 0.000 |
| IC Skew | -0.673 | -3.840000e+00 | -1.034 |
| IC Kurtosis | 1.145 | 1.174300e+01 | 2.099 |
Turnover Analysis
| 1D | 5D | 10D | |
|---|---|---|---|
| Quantile 1 Mean Turnover | 0.340 | 0.765 | 0.785 |
| Quantile 2 Mean Turnover | 0.601 | 0.791 | 0.799 |
| Quantile 3 Mean Turnover | 0.636 | 0.781 | 0.781 |
| Quantile 4 Mean Turnover | 0.607 | 0.791 | 0.800 |
| Quantile 5 Mean Turnover | 0.350 | 0.783 | 0.793 |
| 1D | 5D | 10D | |
|---|---|---|---|
| Mean Factor Rank Autocorrelation | 0.756 | 0.0 | -0.03 |